Coding a Perceptron
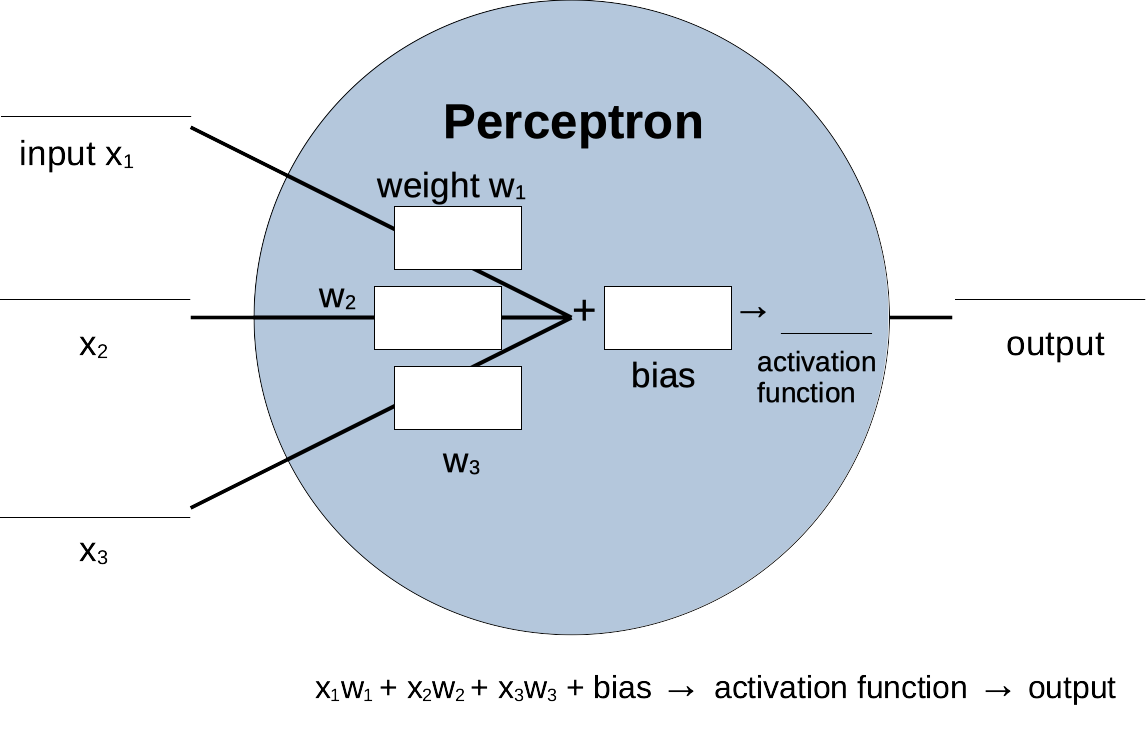
We've developed some theoretical ideas around the concept of a perceptron, and developed some vocabulary around that concepts, including:
- inputs x
- weights w
- bias b
- activation function
- output
An additional term that will be useful is feedforward, which refers to the process of passing inputs into a neuron (or series of neurons) and getting an output.
Let's code a Perceptron object and see how we can use it to help us understand patterns in data.
Coding a Perceptron
Use the Python template or Java template to code a simple perceptron.
#!/usr/bin/env python3
"""
ml1.py
Defines a simple neuron in terms of weights, bias, and input values.
Defines an activation function.
Creates a neuron, gives it inputs, and examines the outputs.
No numpy is used in this example.
"""
__author__ = ""
__version__ = ""
import math
def sigmoid(x):
"""The activation function, the classic f(x) = 1 / (1 + e^(-x))
There are other activation functions that might be better/more common
than this one, but this is good for now.
Negative values approach 0, positive values approach 1.
"""
pass
class Neuron(object):
"""Defines a neuron in terms of its weights and biases
"""
def __init__(self, weights, bias):
"""Parameter weights is a list of weights, where len matches
the number of inputs we'll have. Bias is a single numeric value.
"""
pass
def feedforward(self, inputs):
"""Parameter `inputs` is a list of input values that match the
number of weights we've defined. Multiply each input times its
corresponding weight, add the bias, call the activation function
on the result, and return that value.
"""
pass
def __repr__(self):
return "Neuron[weights=" + str(self.weights) + \
",bias=" + str(self.bias) + "]"
def neuron_test():
"""Constructs a basic neuron, gives it an input, and displays the
output.
"""
weights = [0, 1] # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
x = [2, 3] # Inputs x1 = 2, x2 = 3
result = n.feedforward(x)
print(result) # Should be 0.9990889....
assert result - 0.9990889 < 0.000001
def main():
neuron_test()
if __name__ == "__main__":
main()
/**
* This class describes a Neuron with 2 inputs and 1 output
* Each input, x1 and x2, is multipied by a weight, w1 and w2.
* These are added to a bias b, and ultimately passed through
* an activity function to produce an output.
*
* @author
* @version
*/
public class Neuron
{
private double[] weights;
private double bias;
/**
* The Array of weights includes w0 and w1 (for 2 inputs)
*/
public Neuron(double[] weights, double bias)
{
/* missing code */
}
/**
* Sets up an activation function:
* f(x) = 1 / (1 + e^(-x))
* @param x the sum of the input-weight vectors, plus bias
* @return a value between 0 and 1
*/
public double sigmoid(double x)
{
/* missing code */
}
/**
* Takes an array of input values, multiplies each one
* by its respective weight, adds the bias, gets the
* result of the activation function, and returns the
* final output value.
* @param inputs an array of input values x1, x2, x3, etc.
* @return the output
*/
public double feedforward(double[] inputs)
{
/* missing code */
}
}
Here's a tester you can use with your Neuron class.
/**
* Tests the class Neuron.
*
* @author (your name)
* @version (a version number or a date)
*/
public class NeuronTest
{
public static void main(String[] args)
{
// Single neuron test
Neuron n = new Neuron(new double[] {0,1}, 4);
double[] inputs = {2, 3};
System.out.println(n.feedforward(inputs));
System.out.println("Expected: 0.9990889488055994");
}
}
Network Layers
To increase the power of our data structure, one of the things we can do is expand the number of neurons devoted to processing the input. We can feed the same inputs into a "layer" of neurons, typically drawn in a vertical wall, as well as multiple "hidden" layers (typically arranged left-to-right in a diagram).
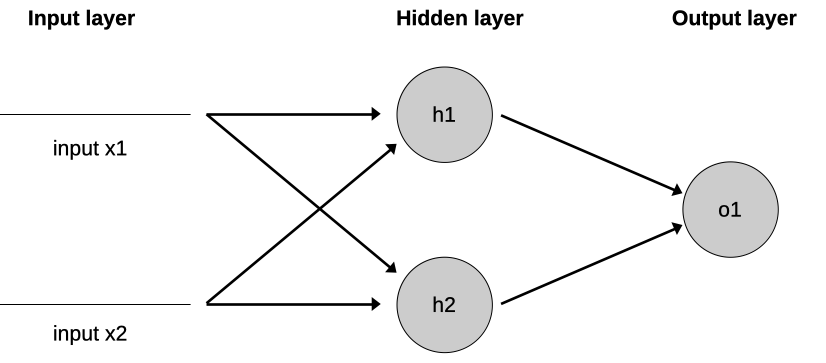
We were getting output from our two inputs with a single neuron before. Why would we now need to feed the two inputs into two neurons in a hidden layer before those results get fed into a final output neuron? The extra hidden layer(s), which typically contain more than just two neurons, allow for better "fine-tuning" of the weights and biases that will go into allowing our algorithm to match patterns.
Ultimately, a fully-functioning neural network may have more of this appearance:
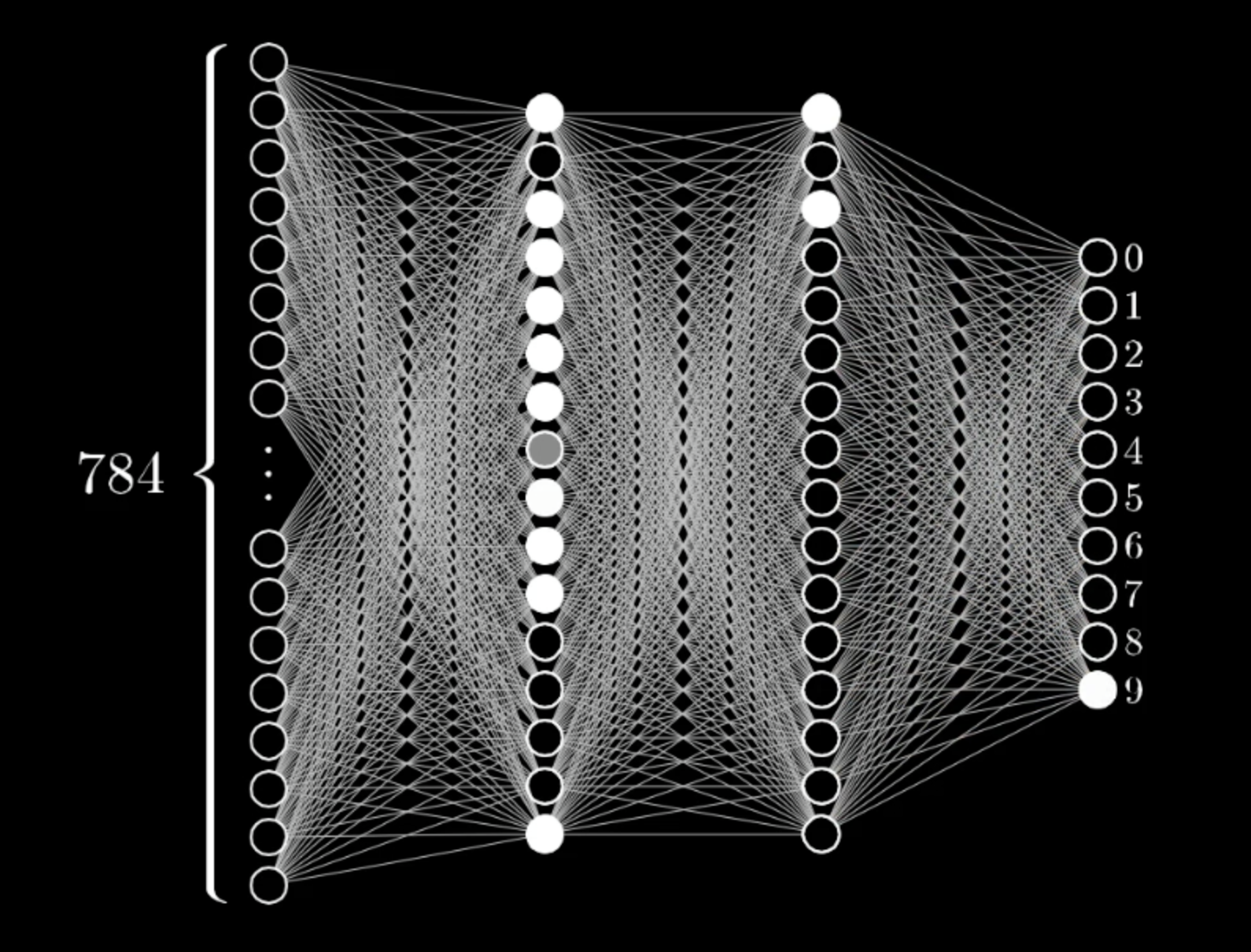
Before we get to that, however, let's see if we can program a simple neural network with a single hidden layer. The complete code is given here.
Including a hidden layer
Look at this code which takes 2 inputs, sends them into a hidden later of two nodes, and then on to a single output node.
Trace through the code to identify what the ouput of the network will be, and put
that into the assert statement.
#!/usr/bin/env python3
"""
ml2.py
Expands on the simple neuron in ml1.py and creates an input layer
of neurons, a hidden layer, and an output result. No numpy is used
in this example.
"""
__author__ = ""
__version__ = ""
import math
def sigmoid(x):
"""The activation function, the classic f(x) = 1 / (1 + e^(-x))
There are other activation functions that might be better/more common
than this one, but this is good for now.
Negative values approach 0, positive values approach 1.
"""
return 1 / (1 + math.exp(-x))
class Neuron(object):
"""Defines a neuron in terms of its weights and biases
"""
def __init__(self, weights, bias):
"""Parameter weights is a list of weights, where len matches
the number of inputs we'll have. Bias is a single numeric value.
"""
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
"""Parameter inputs is a list of input values that match the
number of weights we've defined.
"""
total = 0
for i in range(len(inputs)):
total += inputs[i] * self.weights[i]
total += self.bias
return sigmoid(total)
def __repr__(self):
return "Neuron[weights=" + str(self.weights) + \
",bias=" + str(self.bias) + "]"
class NeuralNetwork(object):
"""Describes a simple neural network with
- 2 inputs
- a hidden layer of 2 neurons h1 and h2
- an output layer with 1 neuron o1
Each neuron has the same weights and biases in this example
- w = [0, 1]
- b = 0
"""
def __init__(self):
"""Initializes a network with 2 input neurons, with same
weights and biases as given here, and an output neuron.
"""
weights = [0, 1]
bias = -1
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
"""Takes the inputs given in the array x and applies the
Neuron's feedforward method to each one to get output
neurons for the hidden layer. Those hidden results are
then fed forward to get a single output result.
"""
out_h1 = self.h1.feedforward(x)
out_h2 = self.h2.feedforward(x)
out_o1 = self.o1.feedforward([out_h1, out_h2])
return out_o1
def network_test():
"""Creates a NeuralNetwork object, initializes an input vector,
gets the output after a feedforward through the network, and
prints the result.
"""
network = NeuralNetwork()
x = [2, 3]
result = network.feedforward(x)
print(result)
assert result - ???? < 0.000001
def main():
network_test()
if __name__ == "__main__":
main()
Min/Max Normalizing
If our neurons are sending output that is in the range 0 - 1, it makes sense to have our input be in the range 0 - 1. (This isn't strictly necessary, but our original data will need to be processed in one form or another, and this is a common-sense strategy.)
If we have a range of input values that we're working with, we can normalize that range to a value between 0 and 1 using this formula:
data = (data - data.min()) / (data.max() - data.min())
What does that mean for our inputs? Here's some random labeled data.
| Height (in) | Weight (lbs) | 0 = male-identifying, 1 = female-identifying |
| 68 | 146 | 0 |
| 64 | 135 | 1 |
| 71 | 150 | 0 |
| 72 | 165 | 0 |
| 71 | 160 | 0 |
| 68 | 135 | 1 |
| 67 | 125 | 1 |
| 69 | 120 | 0 |
| 70 | 177 | 0 |
| 63 | 105 | 1 |
| 67 | 145 | 1 |
Applying the normalization process to this data, we get:
| Height (in) | Weight (lbs) | 0 = male-identifying, 1 = female-identifying |
| 0.5555555555555556 | 0.5694444444444444 | 0 |
| 0.1111111111111111 | 0.4166666666666667 | 1 |
| 0.8888888888888888 | 0.625 | 0 |
| 1.0 | 0.8333333333333334 | 0 |
| 0.8888888888888888 | 0.7638888888888888 | 0 |
| 0.5555555555555556 | 0.4166666666666667 | 1 |
| 0.4444444444444444 | 0.2777777777777778 | 1 |
| 0.6666666666666666 | 0.20833333333333334 | 0 |
| 0.7777777777777778 | 1.0 | 0 |
| 0.0 | 0.0 | 1 |
| 0.4444444444444444 | 0.5555555555555556 | 1 |
This process of converting and cleaning data is something that is common to a lot of machine-learning.
Error; Mean-Square Error
There's another detail that we haven't yet mentioned. Our definition of "learning" over a period of time will be centered on "doing better at getting good results," or more precisely, "making fewer mistakes." The fewer mistakes we make, the better our algorithm is.
When training a supervised learning algorithm, the features (our inputs) will have labels that represent the result we expect for each example in the data set. The label is typically coded as a binary or numeric value to represent a classification: 0 represents "Fail" while 1 represents "Pass", or 0 represents "Male" while 1 represents "Female", etc. (Note that non-binary genders haven't historically been coded for in various database systems; systems that do now allow for non-binary gender classifications should be recognized for taking on the challenges of reconfiguring their systems!)
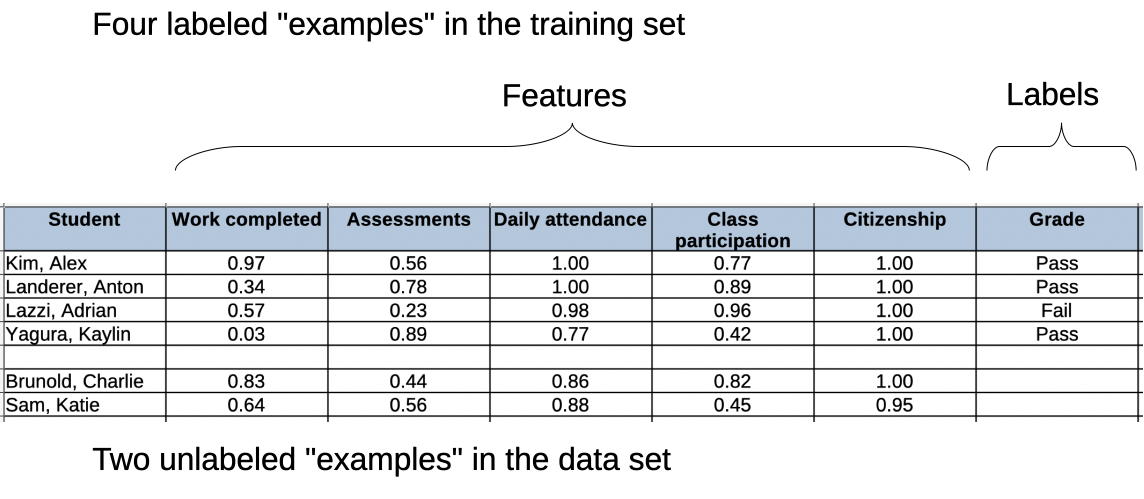
How can we measure our mistakes as we're learning? How can we calculate our error?
Error
There are different strategies for calculating error. One common strategy is to simply get the difference between the expected result (the label) and the result calculated (or predicted by the algorithm. If y is the output of our activation function:

Another common strategy in ML is to calculate the Mean Square Error (MSE) for a series of N values by comparing the expected (or true) result with the result predicted by the algorithm.

Here's a function in Python that does just that:
def mse_loss(y_true, y_pred):
"""Calculates the mean_square_error for two lists
of values. The lower this error is, the better the
predictions of our network will be.
"Training a network" = "minimizing its loss"
"""
n = len(y_true)
total = 0
for i in range(n):
total += (y_true[i] - y_pred[i])**2
return total / n
We've come to the really interesting part of machine learning!
- We can take inputs for our examples
- We can use weights, biases, and an activation function to calculate an output for each example.
- We can compare the outputs from all the examples with our predicted outputs for each example to find out how far off we are.
- ...?
How do we take our error and go back to try to fix our algorithm with new weights and biases?!